Built 26/04/17 09:31commit 4c9ce40
中文 | English
从 文档 开始使用 Claude Managed Agents。
Engineering Blog 里一直有一条持续讨论的主线:如何构建有效 agent、如何为长时间运行工作设计 harness。贯穿这些工作的一个共同点是:harness 往往编码了 Claude 目前“还做不到什么”的假设。但随着模型能力提升,这些假设需要被频繁重新质疑,因为它们会过时。
举一个例子:在之前的工作中,我们发现 Claude Sonnet 4.5 会在接近上下文上限时过早收尾,这种行为有时被称为“context anxiety”。我们通过在 harness 中加入 context reset 解决了它。但当我们把同样的 harness 用到 Claude Opus 4.5 时,这个行为消失了。那些 reset 反而变成了死重。
我们预计 harness 还会持续演化。因此我们构建了 Managed Agents:这是 Claude Platform 上的一项托管服务,它通过一小组足以跨越具体实现变化的接口,替你运行长时 agent,包括我们今天自己在运行的实现也一样。
构建 Managed Agents 的核心挑战,其实是计算领域里的老问题:如何为“尚未被想到的程序”设计系统。几十年前,操作系统通过把硬件虚拟化成足够通用的抽象层来解决这个问题,例如 process 与 file。这些抽象跨越了底层硬件更替而继续存在。read() 命令并不关心自己面对的是 1970 年代的磁盘还是现代 SSD。上层抽象保持稳定,底层实现则可以自由变化。
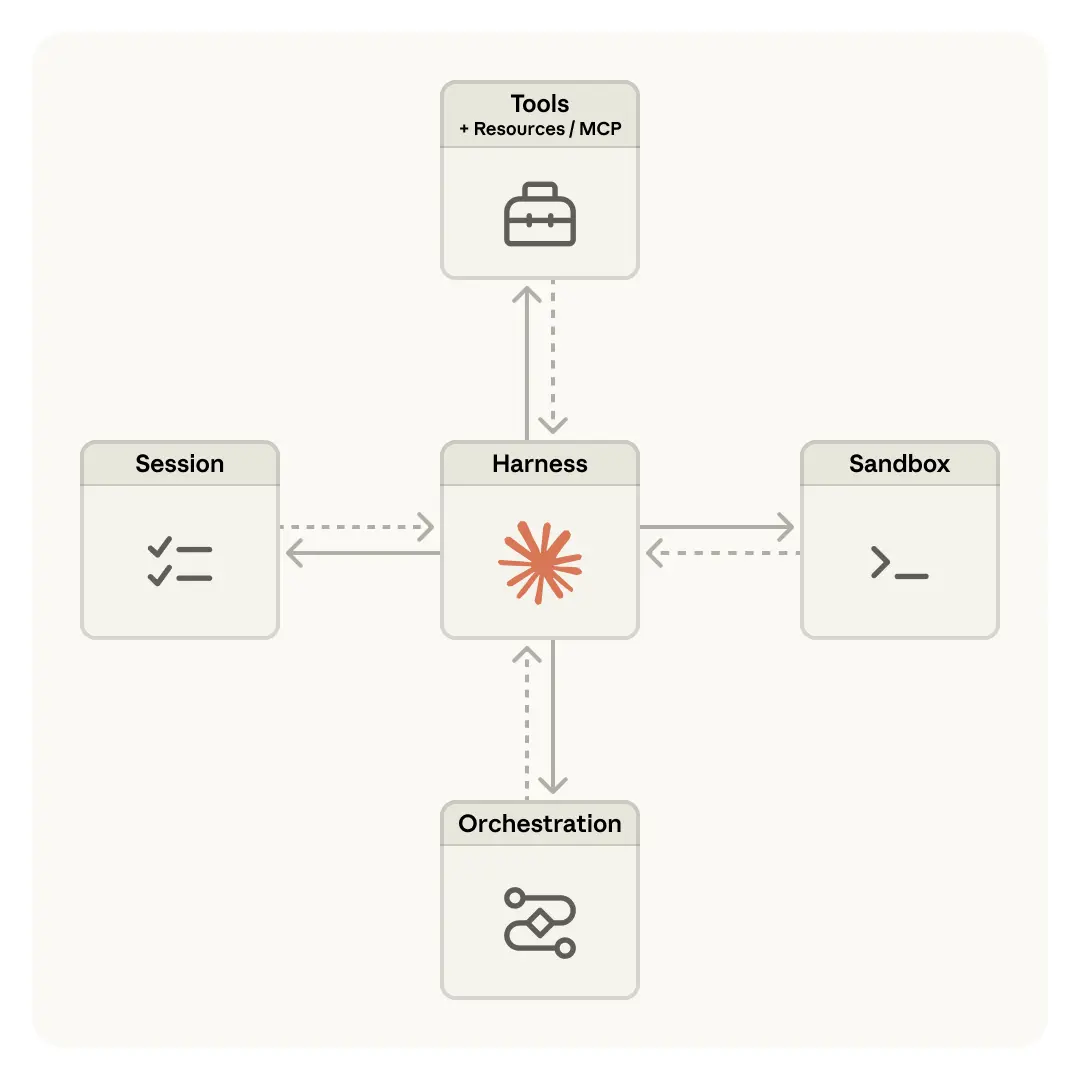
Managed Agents 采用了同样的思路。我们把 agent 的几个组成部分虚拟化出来:session(发生过的一切的追加式日志)、harness(调用 Claude 并把 Claude 的工具调用路由到相应基础设施的 loop),以及 sandbox(Claude 可在其中运行代码和编辑文件的执行环境)。这样一来,每一部分都可以在不扰动其他部分的前提下被替换。我们对这些接口的形状是有立场的,但对其背后究竟跑什么实现并不强加假设。
不要养宠物
一开始,我们把所有 agent 组件都放在单个容器里,这意味着 session、agent harness 和 sandbox 共享同一个环境。这种做法有它的好处,比如文件编辑就是直接系统调用,也不需要设计服务边界。
但把一切都耦合进一个容器,也把我们拖进了基础设施里的一个老问题:我们养了一个宠物。在 pets-vs-cattle 的比喻里,宠物是有名字、需要精心照料、无法承受其丢失的个体;而 cattle 是可互换的。在我们的场景里,这台服务器就成了宠物:容器一旦失败,session 就丢了。容器一旦无响应,我们就得把它“抢救回来”。
抢救容器意味着要调试那些卡死、无响应的 session。我们唯一能看到的是 WebSocket 事件流,但它并不能告诉我们故障究竟出在哪里,所以无论是 harness bug、事件流里的网络丢包,还是容器下线,表象都一模一样。为了查清问题,工程师不得不进入容器 shell;但因为那个容器里往往还带着用户数据,这基本等于我们失去了可调试性。
第二个问题是,harness 默认假设它要访问的所有资源都与自己共处一个环境。比如,当客户希望 Claude 连接到他们自己的 VPC 时,他们只能要么和我们的网络做 peer,要么在自己的环境里运行我们的 harness。一个 baked into harness 的假设,在对接不同基础设施时就变成了阻碍。
把大脑和手分开
我们最终采用的方案,是把我们所说的“大脑”(Claude 及其 harness)与“手”(执行动作的 sandboxes 和 tools),以及“session”(session 事件日志)拆开。每一部分都变成一组对彼此假设最少的接口,因此每一部分都可以独立失败,也可以被独立替换。
Harness 迁出容器。 把大脑和手解耦之后,harness 不再运行在容器里。它调用容器的方式,就和调用其他工具完全一样:execute(name, input) → string。容器于是变成了 cattle。容器死掉时,harness 只会把它当作一次工具调用失败,再把错误传回给 Claude。如果 Claude 决定重试,就可以用标准配方重新初始化一个新容器:provision({resources})。我们不再需要精心照料失败容器。
从 harness 故障中恢复。 Harness 本身也变成了 cattle。由于 session log 位于 harness 之外,harness 崩溃时没有任何必须保活的内部状态。一个新的 harness 被拉起后,可以通过 wake(sessionId) 重启,用 getSession(id) 拿回事件日志,并从上一个事件继续恢复。在 agent loop 期间,harness 会通过 emitEvent(id, event) 把事件持续写回 session,以保留持久记录。

安全边界。 在耦合式设计里,Claude 生成的不可信代码和凭证跑在同一个容器里,所以 prompt injection 只需要说服 Claude 去读取自己的环境变量。一旦攻击者拿到这些 token,就能启动新的、权限更大的 session 并把工作委派出去。缩小权限范围当然是一种缓解,但这本质上仍然是在编码“Claude 无法用受限 token 做什么”的假设,而 Claude 正在越来越聪明。结构性的修复方式,是确保这些 token 永远无法被 Claude 生成代码所在的 sandbox 触达。
我们用两种模式来保证这一点。认证信息可以跟资源绑在一起,也可以保存在 sandbox 之外的凭证库里。以 Git 为例,我们会在 sandbox 初始化时使用仓库自己的 access token 来 clone 仓库,并把它接入本地 git remote。于是 Git push 和 pull 都能在 sandbox 内完成,而 agent 本身永远不会直接接触 token。对于自定义工具,我们支持 MCP,并把 OAuth token 存在安全 vault 中。Claude 通过一个专用 proxy 调用 MCP 工具;proxy 收到与 session 绑定的 token 后,再去 vault 中取出相应凭证并向外部服务发起调用。Harness 本身从头到尾都不需要知道任何凭证。
Session 不是 Claude 的上下文窗口
长时任务经常超过 Claude 的上下文窗口长度,而常见的处理方式都需要你做一些不可逆的取舍,决定保留什么、丢弃什么。我们此前在关于 context engineering 的工作中探索过这些技术。例如,compaction 允许 Claude 把当前上下文窗口压缩成一段总结;memory tool 则允许 Claude 把上下文写入文件,从而支持跨 session 学习。也可以再搭配 context trimming,选择性删除旧工具结果或 thinking blocks 等 token。
但这种不可逆的保留或删除决策会带来失败风险。因为很难提前知道未来轮次究竟会需要哪些 token。如果消息在 compaction 步骤里被转换过,那么 harness 会把那些已压缩消息从 Claude 的上下文窗口里移除,而这些内容只有在另有存储时才可恢复。此前已有工作探索把上下文存成一个位于上下文窗口之外的对象来解决这个问题。例如,让上下文成为 REPL 中的某个对象,再由 LLM 通过写代码去筛选和切片访问它。
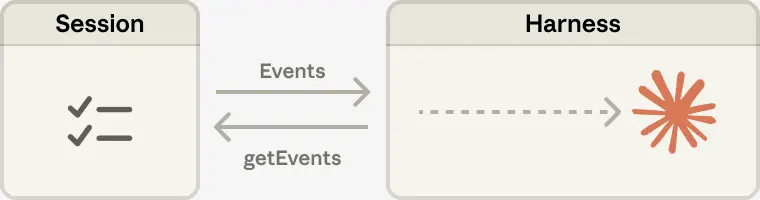
在 Managed Agents 里,session 提供了同样的收益:它充当一个位于 Claude 上下文窗口之外的上下文对象。但它不是被放在 sandbox 或 REPL 中,而是以持久方式存储在 session log 里。接口 getEvents() 允许大脑通过选择事件流中的位置切片来审问上下文。这个接口非常灵活:大脑可以从自己上次读到的位置继续,也可以在某个时刻前回退几条事件看看铺垫,或者在执行某个动作前重新读取相关上下文。
任何取回的 events 还可以在进入 Claude 上下文窗口前先由 harness 做变换。这些变换可以是 harness 所编码的任何逻辑,包括为了提升 prompt cache 命中率而做的上下文组织,以及各种 context engineering。我们把“可恢复的上下文存储”放进 session,把“任意上下文管理”放进 harness,是因为我们无法预知未来模型究竟需要哪种具体的 context engineering。接口的职责是:保证 session 持久且可被审问,而把上下文管理的具体策略留给 harness。
多个大脑,多只手
多个大脑。 把大脑和手解耦之后,我们解决了最早的一个客户抱怨。当团队想让 Claude 对接他们自己 VPC 内的资源时,过去唯一办法是和我们的网络做 peer,因为放着 harness 的容器默认假设所有资源都在自己旁边。Harness 一旦不在容器里,这个假设就消失了。同样的改变还带来了性能收益。最开始我们把大脑放在容器里,意味着有多少个大脑,就要有多少个容器。每一个大脑开始推理之前,都要先等待容器 provision 完成;每一个 session,即便根本不会用到 sandbox,也要先 clone 仓库、启动进程、从我们的服务器拉取待处理 events。
这种空转时间直接体现为 time-to-first-token(TTFT),也就是 session 从接受工作到产出首个响应 token 的等待时长。这是用户最直接能感觉到的延迟。
把大脑和手解耦之后,容器改由大脑通过工具调用 (execute(name, input) → string) 按需 provision,只有真的需要时才启动。因此,那些一开始并不需要容器的 session 就不必先等一个容器。推理可以在编排层从 session log 拉到待处理 events 之后立即开始。基于这套架构,我们的 p50 TTFT 降低了大约 60%,p95 降低了 90% 以上。要扩展到多个大脑,只需要启动多个无状态 harness,并且只在需要时再把它们接到手上。
多只手。 我们还希望每个大脑都能连接到多只手。实际含义是,Claude 必须理解多个执行环境,并决定该把工作发往哪里去做;这比只在单一 shell 里操作是更高的认知负担。我们最初把大脑放在单个容器里,就是因为更早期的模型还做不到这一点。随着智能提升,单容器反而变成了限制:只要那个容器失败,大脑当时伸向的所有手都会一起丢状态。
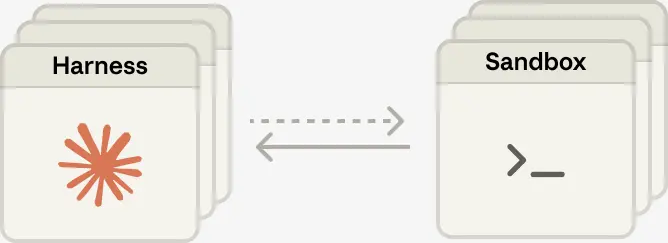
把大脑和手解耦之后,每一只手都只是一个工具:execute(name, input) → string,输入一个名字和参数,返回一个字符串。这个接口可以支持任意自定义工具、任意 MCP server 以及我们自己的工具。Harness 不需要知道某个 sandbox 是容器、手机,还是 Pokemon 模拟器。并且由于任何一只手都不和任何一个大脑绑定,大脑之间还可以互相传递手。
结论
我们面对的是一个老问题:如何为尚未被想到的程序设计系统。操作系统之所以能够跨越数十年,是因为它们把硬件虚拟化为足够通用的抽象,能够容纳尚不存在的程序。借助 Managed Agents,我们希望围绕 Claude 构建一个能容纳未来 harness、sandbox 以及其他组件的系统。
Managed Agents 本质上就是这种意义上的 meta-harness:它不对 Claude 未来具体需要哪种 harness 做假设,而是提供一套允许多种 harness 并存的通用接口。例如,Claude Code 就是一种我们在许多任务中广泛使用的优秀 harness;而我们也已经展示过,任务特定的 agent harness 在狭窄领域中会表现得非常好。Managed Agents 可以容纳这些不同路线,并随着 Claude 的智能提升持续适配。
所谓 meta-harness 设计,意味着我们真正有立场的是 Claude 周围的接口:我们预期 Claude 需要操纵状态(session),也需要执行计算(sandbox)。我们也预期 Claude 需要扩展到多个大脑和多只手。我们把这些接口设计成可以在长时间尺度上可靠且安全地运行。但我们不对 Claude 最终需要多少个、分布在哪里的大脑与手做预设。
致谢
本文作者为 Lance Martin、Gabe Cemaj 和 Michael Cohen。感谢 Nodir Turakulov 与 Jeremy Fox 在相关议题上的讨论,也特别感谢 Agents API 团队和 Jake Eaton 的贡献。